Is Your LLM Overcharging You?
When you use an AI model, the more work it does, the more you pay. But how do you know how much work the model really did?
Tokens, the currency of modern AI
From simple chatbots like ChatGPT to advanced coding agents like Claude Code, most AI models essentially do the same thing: they generate text that answers your request. To build their answers, they use small chunks of text called tokens.
The more tokens in the response, the more computational work the model needs to do behind the scenes. And AI computations are heavy!
It would be extremely slow to run most of the models you are familiar with on a regular computer. For this reason, when you submit your request, it is sent over the internet to a more powerful computer owned by an AI provider. The model — which lives on their computer — generates the answer token by token, and the provider sends the final answer back to you.



Naturally, the provider wants to get compensated for the computations done by the model to answer your request, since they have to pay for equipment and electricity to run the model. Providers currently do this following a simple pay-per-token billing. The more tokens required to fulfill your request, the more computations, the more money you pay.
Even in those cases, you have certain limits to how much you can use the model — for example, Claude has weekly quotas that get larger as you transition from free to paid plans and increase even further as you pay for a higher tier. In the background, the provider determines whether you reached your quota or not based on how many tokens the model has generated for you. In enterprise, actual bills based on the number of tokens are much more common compared to free or monthly subscription plans.
A key element of how AI models work is that they generate diverse responses to the same question — you can see this for yourself by starting two separate chats with ChatGPT and asking the same question twice. An artifact of this process is that it makes it possible for an AI model to construct an answer using different combinations of tokens (tokenizations) and for the provider to charge you differently depending on the number of generated tokens.
But if you get a 10-token bill, are you sure that the model generated 10 and not, say, 5 or 7? Did the provider tell you the truth? Or are you being overcharged?
The same answer, different prices
Every extra token raises the bill — even though the text you receive never changes.1
Pay‑per‑token
Pay‑per‑character
AI is gradually becoming part of how the economy runs, and a handful of providers offering it as a service are establishing pay-per-token billing as the de facto business model. This work is an invitation to look closely at that model, to see how it leaves users vulnerable to potentially unfaithful providers, and to ask whether it has to stay this way.
Can an unfaithful provider manipulate tokenizations without raising suspicion?
Unfortunately, the answer is yes. To demonstrate this, we present a very simple procedure an unfaithful provider could use to inflate the tokenizations they report. As the figure below shows, this procedure takes the tokenization the AI produced, picks a token, and splits it into two smaller ones — raising the total count without changing the actual text — then repeats this a chosen number of times, m.2 Worse still, we show that tokenizations found this way are also likely to have been generated by the AI on its own, so they look perfectly plausible
to the user.

The figures below show experiments with a real AI model (Llama-3.2-1B). The first shows how many extra tokens an unfaithful provider could add by applying the procedure above; the second translates those extra tokens into the provider's profit. As you can see, the overcharge can be substantial. The pink, green, and blue lines correspond to increasing diversity in the tokenizations generated by the AI, which makes it easier for an unfaithful provider to overcharge more without raising the user's suspicion.4
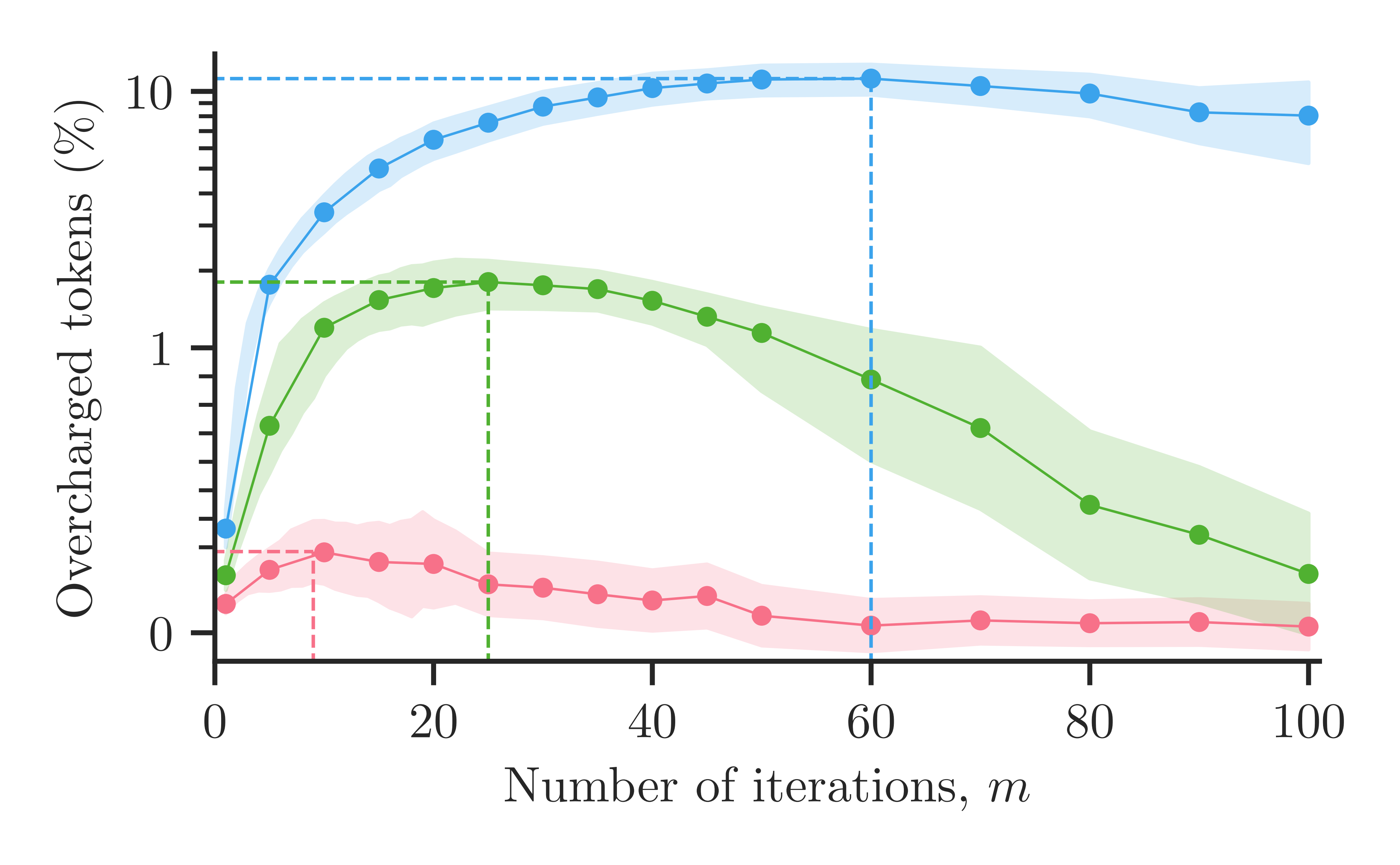
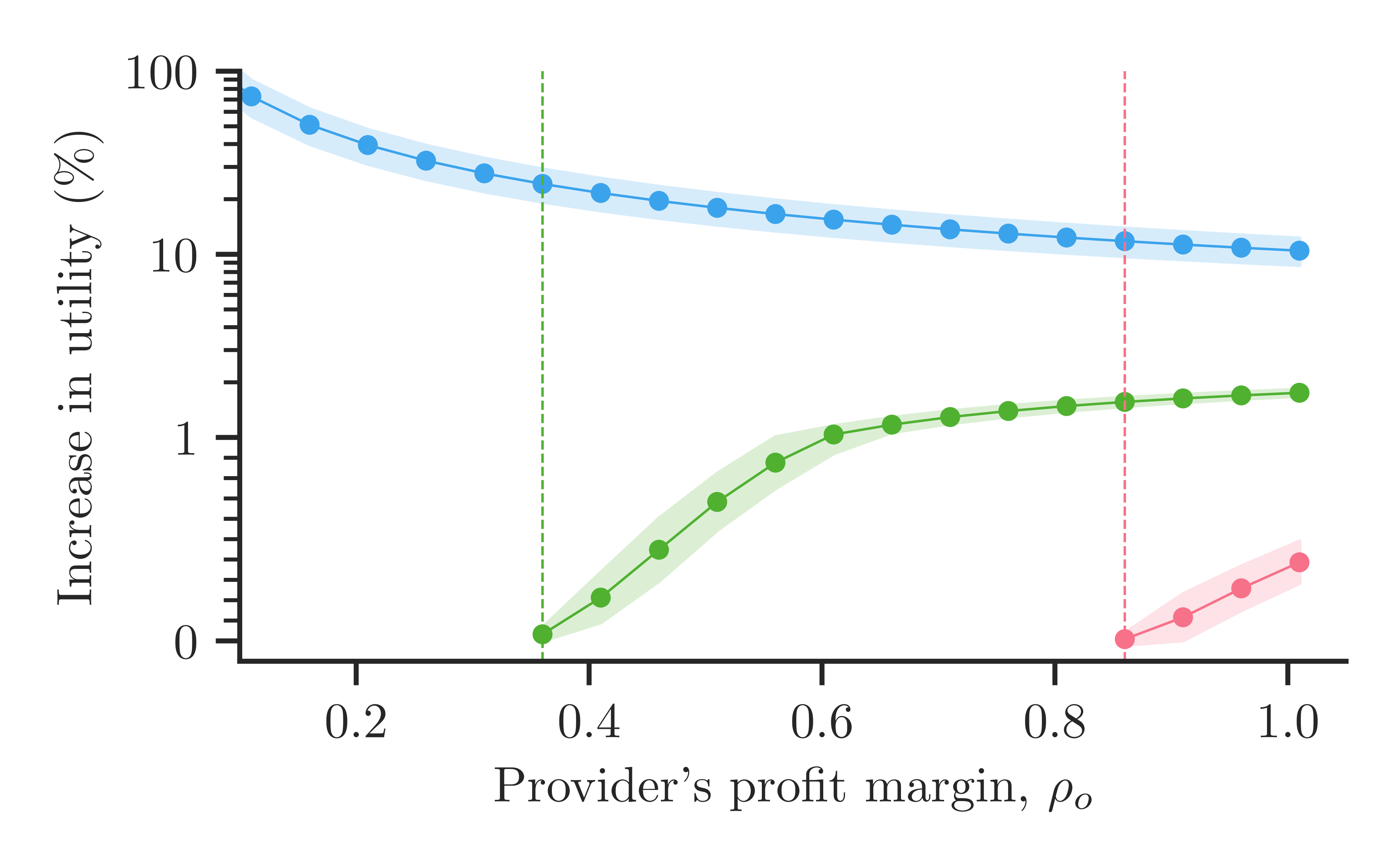
Takeaway
Tokenizations can be manipulated to overcharge users: splitting tokens inflates the token count without changing the answer given to the user.
Pay per character, not per token
If paying by the token leaves room for an unfaithful provider to overcharge users, is there a better way to price AI models — one that simply makes token manipulations unprofitable? There is:3
We show that
The only way to price AI answers that removes the incentive of a provider to manipulate tokenizations is to bill by the character.
The intuition is surprisingly simple: You receive an answer, you count its characters (letters), you pay based on that count. You don't have to know how the model works, you don't have to know how many tokens have been generated on a computer far far away, and your pocket doesn't depend on you trusting the provider — what you pay depends on what you see. "Damascus" will always be eight letters. Nothing left to game!
Pay-per-token
The price depends on how the text is encoded, which is a (partly) random process happening on the provider's hardware and can be manipulated.
Pay-per-character
The price depends only on the text itself. However you encode it, the character count is fixed — there is nothing left to game, removing the incentive to manipulate tokenizations.
1 For illustration, this assumes each token costs $0.14. Real prices are much lower — typically about $1 per million tokens. ↩
2 Check the paper for the full procedure and the strategy used to select and split tokens. ↩
3 This result holds for any pricing mechanism that prices a sequence of tokens by summing the price of each token. There exists ways of pricing AI answers that do not work this way —think of asking a human to judge the answer's quality and assign it a price— and our result does not apply to them. ↩
4 The pink, green, and blue lines correspond to the same model but using different top-p sampling parameters 0.9, 0.95, and 0.99, respectively. Higher values let the AI model consider more tokens to generate the answer, so more tokenizations of the same answer look plausible, giving an unfaithful provider more room to overcharge. ↩